분산원장 2
Tap Root
탭 루트(Tap Root)는 비트코인의 스크립트를 개선하여 프라이버시를 향상시키고 복잡한 트랜잭션과 요소를 개선하기 위한 소프트 포크이다. 비트코인에 탭 루트를 적용시킴으로써 프라이버시, 확장성, 보안을 강화할 수 있다.
Tap Root에 적용되는 기술 및 장점
ECDSA를 통한 슈노르 서명(BIP 340)
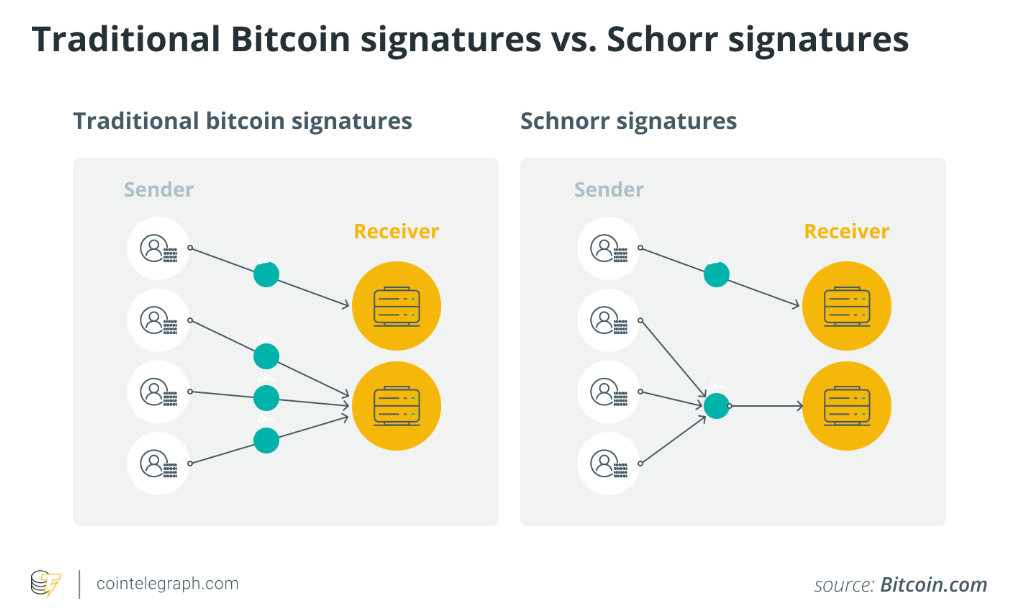
위 그림과 같이 슈노르 서명은 다수의 서명자의 서명을 하나의 서명으로 통합하는 역할을 함으로써 다음과 같은 장점을 가진다.
- 다수의 키를 포함하여 단일하고 고유한 서명을 생성함으로 안전하다.
- 서명을 집계하여 더 많은 트랜잭션을 처리할 수 있어 블록의 공간 절약을 극대화 한다.
- 개인 데이터가 저장된 각 참가자의 트랜잭션 입력을 식별하기가 어려워 프라이버시가 강화된다.
- 서명을 더 이상 변경할 수 없어 이중 지불 문제와 분산화된 원장의 무결성으로부터 안전하다.
탭 루트(BIP 341)
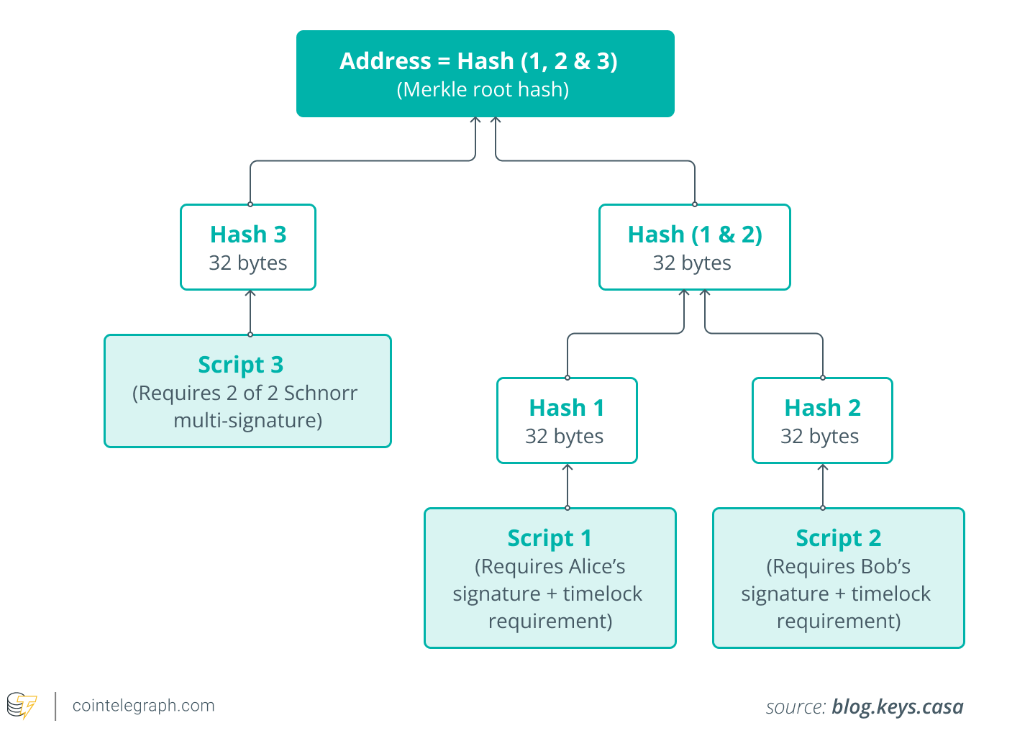
위 그림과 같이 탭 루트의 MAST(Merclized Alternative Script Trees)를 활성화하여, 복잡한 비트코인 트랜잭션을 단일 해시로 압축하여 수수료를 줄이고 메모리 사용을 최소화하여 비트코인 확장성을 개선한다.
탭 스크립트(BIP 342)
탭 루트 스크립트 경로 지출에 사용되는 스크립팅 언어로 슈노르 서명의 효율성을 활용하고 향후 업그레이드 더 많은 유연성을 제공할 수 있다.
Bloom Filter
블룸필터(Bloom Filter)란 특정 원소가 집합에 속하는지 검사하는데 사용할 수 있는 확률형 자료 구조이다. 따라서 확률적 검색 필터로 많은 양의 데이터를 줄여서 공간 효율적으로 빠르게 검색 가능하다.
이러한 점은 SPV(Simplified Payment Verification) 클라이언트라고도 하는 경량 클라이언트가 전체 블록 데이터를 다운로드하지 않고도 일부 트랜잭션이 블록에 포함되었는지 여부를 확인할 수 있게 해준다.
Bloom Filter 동작 방식(Ex. BlackList)
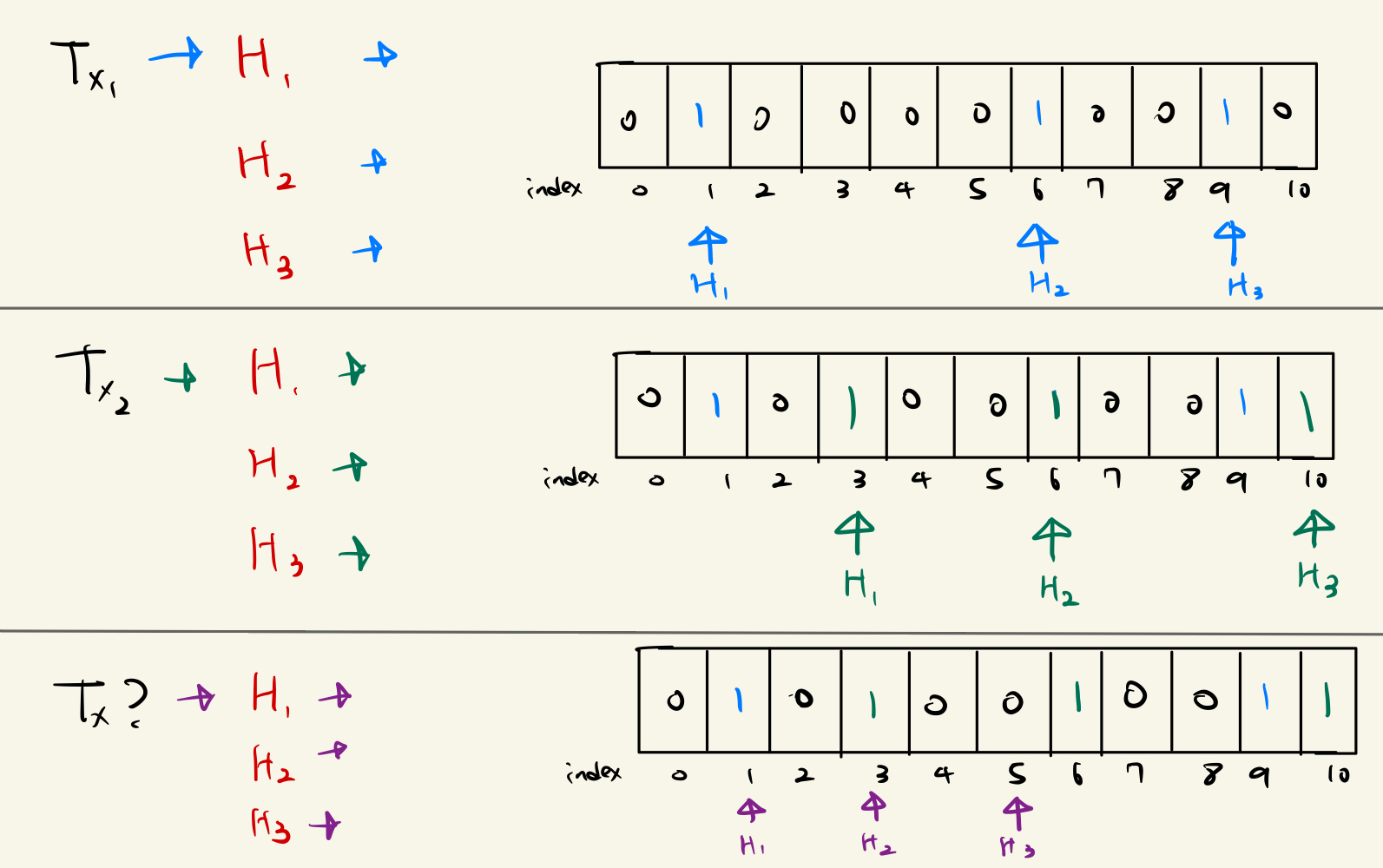
위 그림과 같이 공통적으로 H1, H2, H3과 같은 해시 함수를 정하고, 각 트랜잭션의 해싱 값을 배열 인덱스 값을 1로 수정함으로써 블룸필터를 작성해나간다.(이 때, Tx2와 같이 해싱 값에 해당하는 배열 인덱스 값이 이미 1이면 수정하지 않는다.)
이후 블룸필터를 통해 조회 시, 조회하려는 트랜잭션을 블룸필터 작성과 같이 해싱하고 해당 값이 전부 1일 경우 유효한 트랜잭션이며, 하나라도 0일 경우 유효하지 않은 트랜잭션으로 판단된다.
위 과정은 단순화한 동작방식이지만, 이와 같은 원리를 통해 블록체인에서는 각 블록의 헤더를 신속하게 탐색하여 연관된 정보를 포함하고 있는지 블룸 필터에서 찾는다.(e.g., 이더리움 256비트 블룸필터)
Bloom Filter 특징
블룸 필터는 길이 N의 이진 배열과 1부터 N까지의 출력값을 갖는 J개의 해시함수를 가지고 있는데, 이 N과 J를 조절함으로써 정확도와 프라이버시 보호 수준을 조절할 수 있다.
확률적이기 때문에 오탐률 또한 존재하며, FN은 보장 가능하지만, FP는 100% 일치하지 않는다.
- FN : 특정 원소가 실제로 존재하지 않고, 존재하지 않다고 판단
- FP : 특정 원소가 실제로 존재하지 않지만, 존재한다라고 판단
또한, 있는지 없는지만 보기 때문에 삽입만 가능하며, 제거도 되지 않는다.
Bloom Filter 사용 예
블룸필터는 처리능력 대비 적은 메모리 공간을 필요로 하는 장점 때문에 DB 이외에도 많은 곳에서 사용된다.
- IP 주소 검색 및 차단 필터링
- 문자열 맞춤법 교정
- 가상화폐
- 라우터
- 크롬 브라우저
- 빅데이터 환경
DAG(Directed Acylic Graph)
방향성 비순환 그래프(DAG)
방향성 비순환 그래프는 방향 그래프 중 순환이 발생하지 않는 그래프를 의미한다. 즉, 한 정점에서 시작해 다시 해당 정점으로 돌아오지 않는 일방향성이라는 특성을 가진다.
암호화폐에서 DAG
블록체인 구조와 다르게 DAG는 블록의 개념이 존재하지 않으며, 그래프의 각 정점은 블록이 아닌 개별 트랜잭션이다. 따라서 채굴 또한 필요하지 않으며,대신 각 트랜잭션들은 서로를 참조함으로써 해당 트랜잭션의 유효성을 검증한다.
DAG 트랜잭션 검증
- 노드가 트랜잭션을 네트워크에 제출한다.
- 새로운 트랜잭션은 네트워크 내에 있는 이전 트랜잭션을 참조해야 네트워크에 승인되기 때문에, 이전 트랜잭션을 찾는다.
- 꼭 직전에 올라온 트랜잭션이 아니어도 상관없으며,
- 시스템이 안전하게 성장하기 위해 더 많이 검증된 트랜잭션을 채택하도록 한다.
- 이전 트랜잭션을 찾았다면, 해당 트랜잭션의 유효성을 검사한다.
- 그래프 가장 처음 트랜잭션까지의 경로로 올라가면서, 해당 트랜잭션이 유효한지 확인한다.
- DAG에서는 자신이 참조하는 트랜잭션의 전체 경로를 확인하고 잔고가 충분한지 트랜잭션을 검증함으로써 이중 지불을 방지한다.
- 만약, 해당 트랜잭션이 유효하지 않다면 새로운 트랜잭션은 이 트랜잭션을 참조하지 않고 다른 이전 트랜잭션을 참조한다.
- 그래프 가장 처음 트랜잭션까지의 경로로 올라가면서, 해당 트랜잭션이 유효한지 확인한다.
- 이후 새로운 트랜잭션이 해당 트랜잭션을 참조하여 유효성 검사를 해줌으로써 승인 된다.
DAG 장단점
장점
- 블록 시간 제한 없이 트랜잭션 처리 가능 : 확장성, 속도 우수
- 마이닝 없음 : 채굴자에게 낼 수수료 또한 없고 ,PoW에 대한 에너지 사용도 없음
단점
- 완전한 탈중앙화 아님 : 제 3자의 개입없이 DAG가 커나갈 수 있을지 미지수
- 다양한 규모에서 테스트되지 않음
DHT
Hash Table
Hash Table이란 키를 입력값르로 해시 함수를 사용하여 변환한 해시 값을 색인으로 삼아 키와 데이터를 저장하는 자료구조이다.
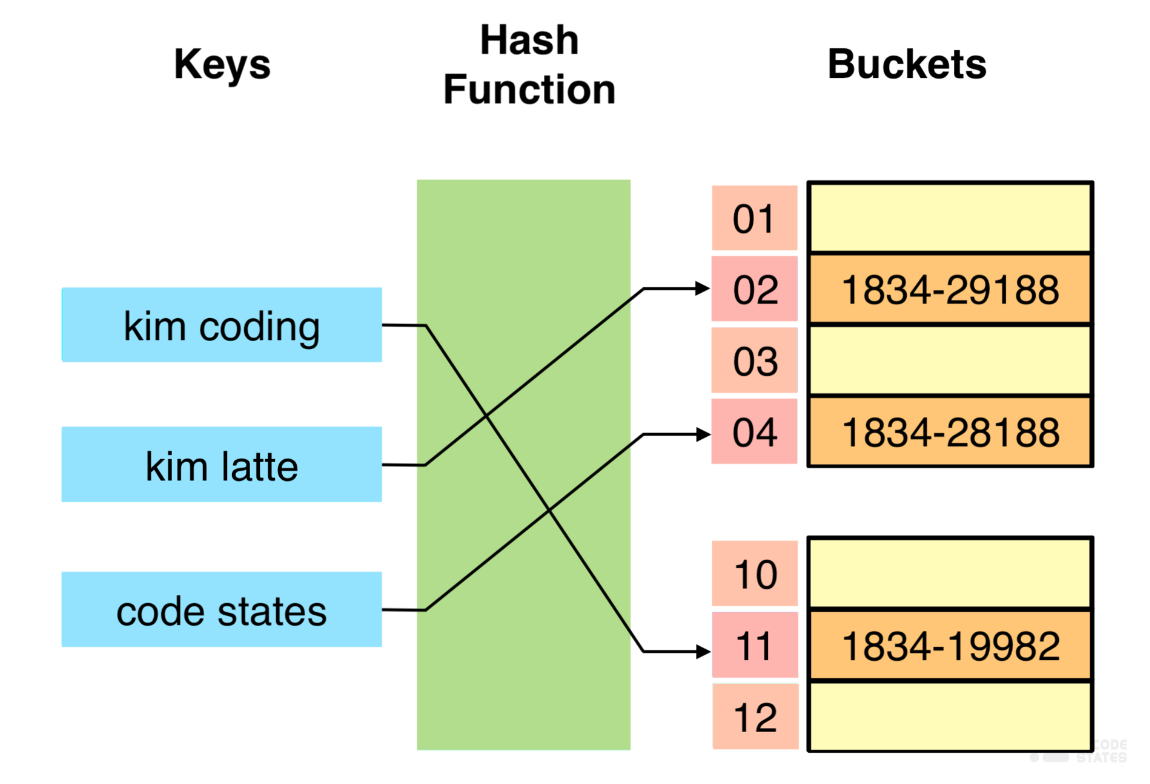
- 키(Key) : 고유한 값으로 해시 함수의 입력값이다.
- 해시함수(Hash Function) : 키를 해시로 바꿔주는 역할을 한다.
- 이 때, 해시 특성상 해시 충돌이 일어날 수 있어 해당 확률을 줄이는 것이 중요하다.
- 해시(Hash) : 데이터의 키 역할이 되며, index와 같이 상용한다.
- 데이터(Value) : 저장소에 최종적으로 저장되는 값으로 index과 매칭되어 저장된다.
Hash Table 특징
- Hash Table에서 저장, 삭제, 검색 과정은 모두 평균적으로 O(1)로 매우 빠르다.
- 해시 함수에 키 값을 넣어 만들어진 해시 값과 일치하는 색인을 찾아 저장하거나 삭제, 검색한다.
- 만약 해시 충돌이 발생할 경우, 모든 색인 혹은 데이터를 찾아봐야 해서 O(n)이 될 수도 있다.
- 다만, 해시충돌이 발생할 수 있고, 데이터가 저장되기 전에 저장공간을 미리 만들어놔야해서 공간 효율성이 떨어진다.
- 해시함수가 복잡하다면 해시값을 만들어내는데 많은 시간이 소요된다.
DHT(Distributed Hash Table)
DHT(분산 해시테이블)는 해시 테이블을 활용해 키-값 쌍 방식으로 P2P환경에서 데이터를 분산 저장 및 검색하는 데이터베이스이다.
DHT에 데이터를 저장하는 방법
- 해시 테이블의 범위를 0~N이라고 한다.
- 호스트는 M명이고 각각 공유해야할 데이터를 가지고 있다.
- 각 해시테이블의 인덱스에 호스트의 IP주소를 넣는다.
- Ex. 123.123.123.123 -> 3
- 각 호스트들은 자신의 다음 호스트 IP주소를 알게된다.
- 해시 테이블에 인덱스에는 호스트 IP 주소 이외에도 데이터의 위치를 저장한다.
DHT가 데이터를 검색하는 방법
검색하는 호스트는 자신과 가장 가까운 호스트에게 검색할 데이터를 묻고, 검색하는 호스트와 가장 가까운 호스트에게 데이터의 위치가 없다면,
가장 가까운 호스트가 검색하는 호스트처럼 순회하는 구조로 묻는다. 따라서 O(log(N))의 시간복잡도를 가진다.
DHT vs Blockchain
DHT는 분산 데이터베이스이다. 즉 데이터가 노드 간에 균일하게 분산되고, 데이터 검색시 시간복잡도는 O(log(N))으로 확장성이 매우 높아 네트워크를 분할하기 위한 효율적인 구조를 제공한다.
하지만 Blockchain은 분산 데이터 구조이지만, 각 노드는 전체 데이터를 저장하며, 데이터의 위변조를 방지에 목적이 있어 블록체인의 모든 데이터는 노드간의 합의로 검증되어야 한다.
IPFS
IPFS(InterPlanetary File System)는 분산형 파일 시스템에 데이터를 저장하고 인터넷으로 공유하기 위한 프로토콜로, P2P 네트워크이다.
기존의 HTTP 프로토콜 방식은 데이터가 위치한 곳의 주소를 찾아가서 요청한 컨텐츠를 가져오는 방식이었지만, IPFS는 전 세계의 여러 컴퓨터에서 분산 저장된 각 데이터 조각을 가져와 하나로 합쳐서 보여주는 방식으로 동작한다.
프로토콜, 웹, 모듈러, 암호화, P2P, CDN, 네임서비스 모든 것을 아우른다.
IPFS 특징
분산화(Decentralization)
IPFS는 중앙 서버가 아닌 분산된 환경의 여러 피어로부터 파일을 다운로드 받는다.
- 안정적인 네트워크 지원
- 콘텐츠 검열 어려움
- 웹 속도 높음 : 주변 가까운 피어에게 파일 받아오기 때문에
콘텐츠 어드레싱(Content-addressing)
/ipfs/QmQPLMruQdHeEoPauzzPqkXQbgTmcbozrYxG6mrFDQ9MZ8?filename=default.jpeg와 같이 콘텐츠를 주소 기반으로 표현한다.
- ipfs/[CID]?filename=[파일 명] 구조 이며, CID는 콘텐츠 식별자로, 콘텐츠 내용의 해시값이다.
- 매번 콘텐츠가 업데이트될 때마다 새로운 링크를 보내는 것은 비효율적이기 때문에 IPNS, MFS, DNSLink를 참고해서 보완이 가능하다.
참여(Participation)
IPFS는 소유와 참여를 기반으로 동작하며, 많은 사람이 서로 파일을 소유하고 사용가능하게 만드는 데 초점을 맞춘다.
사람들이 적극적으로 참여해야 정상적으로 작동한다.
IPFS 동작방식
1. 콘텐츠 어드레싱을 통한 고유 식별
해시를 통해 콘텐츠를 식별한다. 그러나 이러한 시스템의 데이터 구조는 상호 운용 가능하지 않고 서로 연동되지 못하기도 하기 때문에 IPLD라는 프로젝트가 시작되었다.
2. DAG
각 노드에는 노드 콘텐츠의 해시가 있는 Merkle DAG를 사용한다. 이를 위해 콘텐츠를 블록 단위로 분할하고 두 개의 유사한 파일이 있는 경우, Merkle DAG 일부를 공유한다. 이와 같이 매번 완전히 새로운 파일을 만드는 대신 새롭거나 변경된 부분만 전송 받을 수 있다.
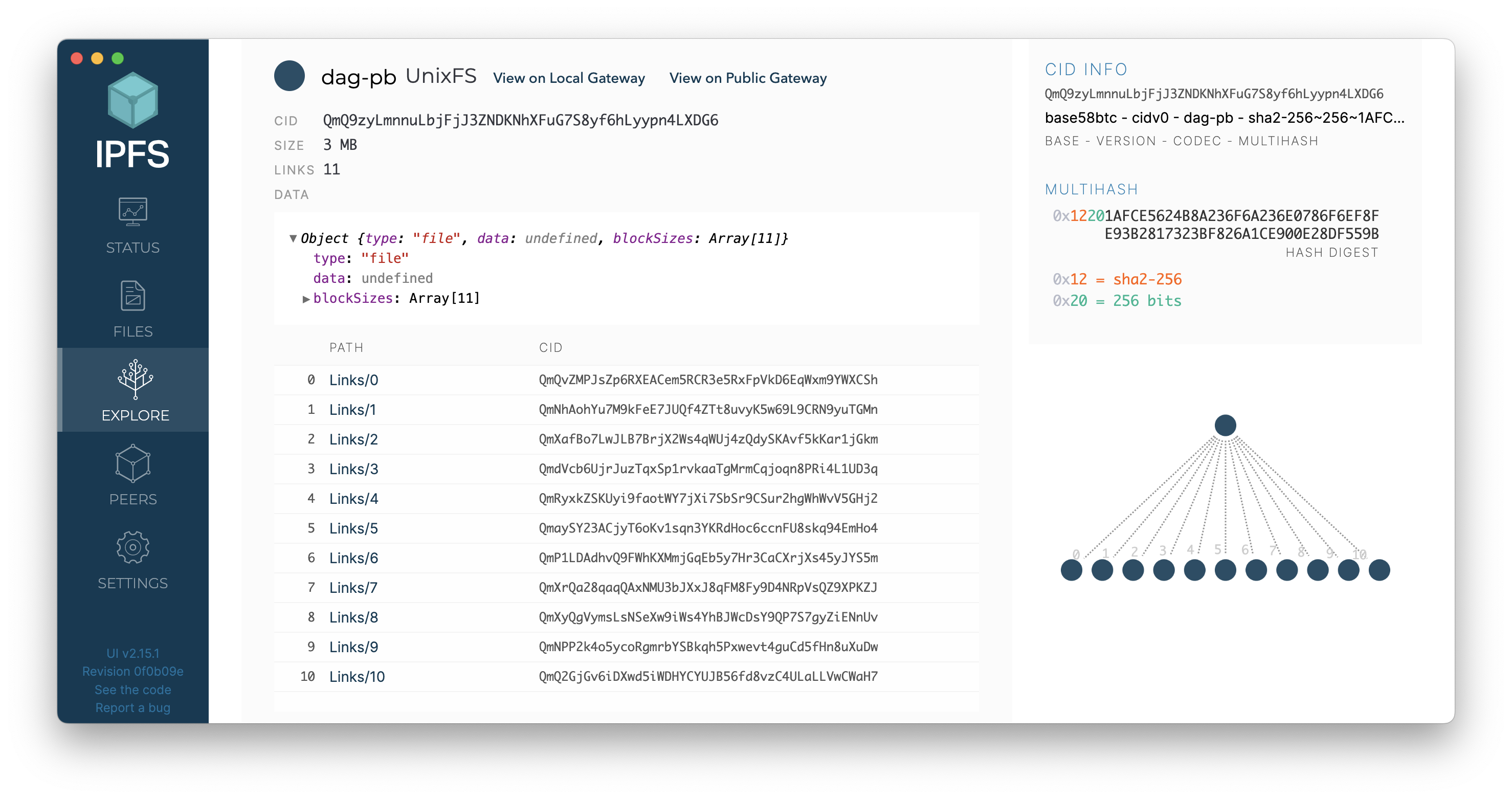
3. DHT
어떤 피어가 콘텐츠를 호스팅하고 있는지 탐색하기 위해 DHT를 사용한다.
IPFS는 DHT를 제공하고 서로 연결하고 소통하는 피어를 처리하기 위해 libp2p라는 프로젝트를 제공한다.
피어를 찾고 난 후, 콘텐츠 내용을 가져오는 총 두 번의 쿼리가 필요하다.
다른 피어에게 블록을 요청하고 블록을 보내기 위해서는 Bitswap이라는 모듈을 사용한다.
요청한 블록이 도착하면 콘텐츠를 해시하여 CID를 얻고 이를 요청한 CID와 비교함으로써 정확한 데이터를 받았는지 검증가능하다.
Pruning
프루닝은 경량화 기법의 하나로, 인공 지능 분야에서 검색 모델을 학습한 후에 불필요하거나 중요도가 낮은 노드 등을 제거하는 기술을 일컫는다.
블록체인에서 오래된 블록체인 데이터를 자동으로 삭제하기 위해 사용된다.
비트코인 프루닝(Block File Pruning)
비트코인이 성장함에 따라 데이터도 커져, 프루닝을 통해 비트코인 용량 최적화를 하려고 한다. 비트코인이 블록을 실행 및 검증하는 데 중요한 것은 트랜잭션 Input에 대한 Output이 사용 가능한지 여부이다. 이를 효과적으로 처리하기 위해 비트코인 클라이언트는 UTXO를 사용하며, 검증된 UTXO set이 존재한다면, 모든 데이터를 받아올 필요가 없다. 따라서 블록이 교체될 경우, 빠진 블록의 트랜잭션을 복구하기 위해 비교적 최신 정보만을 가지고 동작한다.
이더리움 프루닝(State Trie Pruning)
이더리움은 머클 페트리샤 트리(상태전이 일반 머클 확장 패트리샤 트리)로 State Trie Pruning을 진행함으로써 공간적인 측면에서 효율적이나, 이더리움은 블록의 Finality를 보장하지 않고, 과거의 State에 계속 엮여있기 때문에 노드를 바로 지울 수 없다. 또한, State Trie의 노드는 DB에 저장되는 영구 메모리이기 때문에 만약 State Trie가 비정상적인 상태가 된다면 복구할 방법이 없다. Trace를 사용하여 프루닝을 진행할 수도 있지만 Trace에 추가적인 메모리나 Stop-the-world에 의해 생기는 성능 문제 등이 먼저 해결되어야 한다. 따라서 Geth에서는 매우 한정적으로 캐시를 통해 State Trie Pruning을 진행하지만, Fast sync와 같은 방법을 권장한다.
본 포스팅은 코드스테이츠 BEB 과정을 수강하며 작성한 글입니다.
Reference
https://cointelegraph.com/bitcoin-for-beginners/a-beginners-guide-to-the-bitcoin-taproot-upgradehttps://academy.binance.com/en/articles/what-are-nodes
https://academy.binance.com/ko/glossary/bloom-filter
https://academy.binance.com/ko/articles/what-is-a-directed-acyclic-graph-dag-in-cryptocurrency
https://stackoverflow.com/questions/26415908/whats-the-difference-between-distributed-hashtable-technology-and-the-bitcoin-b
https://medium.com/codechain-kr/%EB%B9%84%ED%8A%B8%EC%BD%94%EC%9D%B8-%EC%9D%B4%EB%8D%94%EB%A6%AC%EC%9B%80-%EB%A6%AC%ED%94%8C-%ED%94%84%EB%A3%A8%EB%8B%9D-%EB%B9%84%EA%B5%90-d65729c4a92a