[데이터베이스] 관계형 데이터베이스 - SQL DataBase
관계형 데이터베이스(Relational DB)
필요성
- In-Memory
- 변수를 만들어 저장하는 경우 프로그램이 실행될때만 해당 데이터가 유효하다.
- 데이터 보호, 수명에 취약
- File I/O
- 휘발성 데이터는 아니지만 데이터가 필요할 때마다 파일 전체를 읽어서 가공해야 한다.
- 이러한 방식은 비효율적이며, 데이터량이 많아질수록 효율이 떨어진다.
-> 데이터베이스 필요!
SQL
SQL은 데이터베이스 언어로, 주로 관계형 데이터베이스에 사용된다. 이를 통해 데이터베이스에 쿼리를 보내 원하는 데이터를 CRUD할 수 있다.
기본 쿼리문
데이터베이스 생성
CRETATE DATABASE [DATABASE_NAME];
데이터베이스 사용
USE [DATABASE_NAME];
이를 통해 해당 데이터베이스에 접근해서 TABLE 핸들링을 할 수 있다.
테이블 생성
CREATE TABLE user (
id int PRIMARY KEY AUTO_INCREMENT, -- pk로 지정 데이터가 들어올 때마다 1씩 증가
name varchar(255),
email varchar(255)
);
테이블 정보 확인
DESCRIBE user;
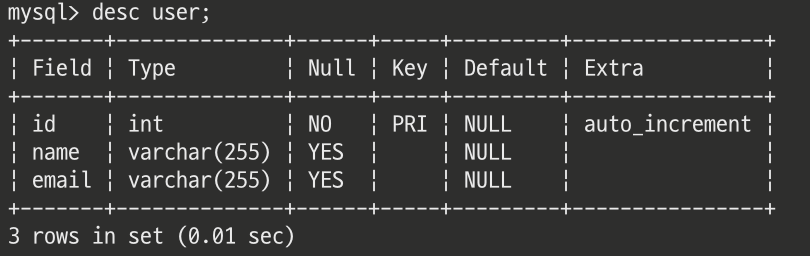
위 그림과 같이 필드, 타입, Null 허용, Key, Default값, 부가 내용 등 테이블 정보를 확인할 수 있다.
SELECT
SELECT id;
SELECT *; -- 전부
SELECT는 데이터셋에 포함될 특성을 지정한다.
FROM
SELECT id -- id를 지정
FROM user; -- user 테이블에 있는
FROM은 결과를 도출해낼 데이터베이스 테이블을 명시한다. 테이블 관련 작업시 반드시 입력해야 한다.
WHERE
SELECT * -- 모든 컬럼을 지정
FROM user -- user 테이블에 있는
WHERE name = "kim"; -- 근데 이제 name이 kim인
SELECT *
FROM user
WHERE name NOT IN ('kim'); -- 근데 이제 name이 kim이 아닌
필터 역할을 하는 쿼리문으로 선택적으로 사용 가능하며, 부등호 연산, LIKE(특정 문자열 포함), IN(특정값 포함), IS NULL(null인지 확인), NOT(부정)과 같이 사용할 수 있다.
ORDER BY
SELECT * -- 모든 컬럼을 지정
FROM user -- user 테이블에 있는
ORDER BY id -- id를 기준으로 오름차순 정렬을 한다.
SELECT *
FROM user
ORDER BY id DESC; -- DESC는 내림차순
데이터 결과를 정렬한다. WHERE과 마찬가지로 선택적이다.
LIMIT
SELECT * -- 모든 컬럼을 지정
FROM user -- user 테이블에 있는
LIMIT 200; -- 데이터 개수는 200개만
데이터 결과의 개수를 제한할 수 있다. 선택적이다. 가장 마지막 순서로 넣는다.
DISTINCT
SELECT DISTINCT name -- name이 같은 데이터를 하나로
FROM user; -- user 테이블에 있는
고유한 값을 반환 받을 때 사용한다.
INNER JOIN
SELECT * -- 모든 컬럼 지정
FROM user -- user 테이블에 있는
JOIN phone ON user.id = phone.user_id; -- user테이블과 phone테이블을 조인
INNER JOIN은 둘 이상의 테이블을 서로 공통된 부분으로 연결한다.
OUTER JOIN
SELECT * -- 모든 컬럼을 지정
FROM user -- user 테이블에 있는
LEFT JOIN phone ON user.id = phone.user_id; -- user테이블과 phone테이블을 조인하는데 left <- 니까 user 데이터는 모두 살리고 왼쪽에만 있는 데이터가 오른쪽에 없으면 NULL
OUTER JOIN은
- LEFT OUTER JOIN
- RIGHT OUTER JOIN
- FULL OUTER JOIN
으로 조회하고자 하는 데이터에 따라 적절하게 사용하면 된다.
SQL 내장 함수
GROUP BY
데이터를 조회할 때 그룹으로 묶어서 조회한다.
SELECT * FROM customers -- 소비자들 정보를 모두 조회
GROUP BY address; -- 주소에 따라 묶어서
HAVING
GROUP BY로 조회된 결과를 필터링한다.
SELECT CustomerId, AVG(Total) -- customerId와 총합 평균을 조회한다.
FROM invoices -- invoice테이블로부터
GROUP BY CustomerId -- CustomerId별로
HAVING AVG(Total) > 6.00; -- 총합평균이 6.00초과인것만
그룹화 이전에 데이터를 필터해야한다면 WHERE을 사용한다.
COUNT()
레코드 개수를 반환한다.
SELECT *, CONUT(*) FROM customers -- 해당 레코드의 개수를 반환한다.
GROUP BY address; -- 주소로 묶어서
SUM()
레코드의 합을 반환한다.
SELECT InvoiceId, SUM(UnitPrice) -- UnitPrice 필드의 합을 구한다.
FROM invoice_items -- invoice_items 테이블에서
GROUP BY InvoiceId; -- InvoiceId로 묶어서
AVG()
레코드의 평균값을 반환한다.
SELECT TrackId, AVG(UnitPrice) -- UnitPrice 필드의 평균을 구한다.
FROM invoice_items -- invoice_items 테이블에서
GROUP BY TrackId; -- TrackId로 묶어서
MAX(), MIN()
레코드의 최대, 최소값을 반환한다.
SELECT CustomerId, MIN(Total) -- Total 필드의 최소값을 구한다.
FROM invoices -- invoices 테이블에서
GROUP BY CustomerId; -- CustomerId로 묶어서
SELECT 실행 순서
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY 순으로 동작한다.
EX
SELECT CustomerId, AVG(Total)
FROM invoives
WHERE CustomerId >= 10
GROUP BY CustomerId
HAVING SUM(Total) >= 30
ORDER BY 2;
- FROM : invoice 테이블에서
- WHERE : CustomerId가 10이상인 레코드를
- GROUP BY : CustomerId로 묶어서
- HAVING : Total 총 합이 30이상인 레코드
- SELECT : 중 Customer 필드와 Total 필드의 평균갑을 구해서 조회한다.
- ORDER BY : 조회 결과를 AVG(Total)을 기준으로 리턴한다.
ACID
ACID란 데이터베이스 내에서 일어나는 하나의 트랜잭션의 안전성을 보장하기 위해 필요한 성질이다.
- Atomicity
- Consistency
- Isolation
- Durability
Atomicity(원자성)
원자성이란 하나의 트랜잭션에 속해있는 모든 작업이 전부 성공하거나 전부 실패해서 결과를 예측할 수 있어야 한다. 이는 예를 들어 A-> B로 송금을 진행할 때, A에서 출금만 되고 B에 입금이 안될 경우 데이터가 오염되기 때문에 이를 방지한다.
Consistency(일관성)
일관성이란 데이터베이스 상태가 일관되어야 한다는 성질이다. 따라서 트랜잭션은 데이터베이스의 상태를 변경할 수 없다. 즉 트랜잭션이 데이터베이스 제약이나 규칙을 위반할 수 없다.
Isolation(격리성, 고립성)
격리성이란 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다. 그렇기 때문에 트랜잭션 간 작업 내용을 알 수 없으며 연속적으로 실행될 때와 같이 데이터베이스 상태가 동일해야 한다.
Durability(지속성)
지속성이란 하나의 트랜잭션이 성공적으로 수행되었다면 해당 트랜잭션에 대한 로그가 남아야 한다. 만약에 런타임 오류나 시스템 오류가 발생하더라도 해당 기록은 영구적이어야 한다. 이는 시스템 복구를 위해 꼭 필요하다.
설계
키워드
- 데이터(Data) : 각 항목에 저장되는 값
- 테이블(Table or Relation) : 사전에 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적
- 칼럼(Column or Field) : 테이블의 한 열
- 레코드(Record or Tuple) : 테이블의 한 행에 저장된 데이터
- 키(Key) : 테이블의 각 레코드를 구분할 수 있는 값, 각 레코드마다 고유한 값을 가지며, 기본키와 외래키 등이 있다.
관계 종류
1:1 관계
하나의 레코드가 다른 테이블의 레코드 한 개와 연결된 경우로,
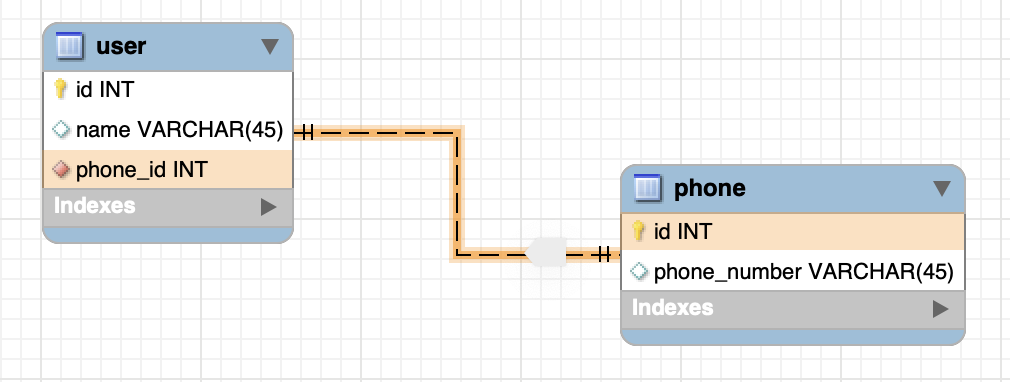
위 그림과 같이 하나의 유저가 하나의 핸드폰 번호를 가질 수 있는 구조이다. 그러나 이러한 경우 user 테이블에 phone_number를 직접 저장하는 게 나을 수 있다.
1:N 관계
하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우로,
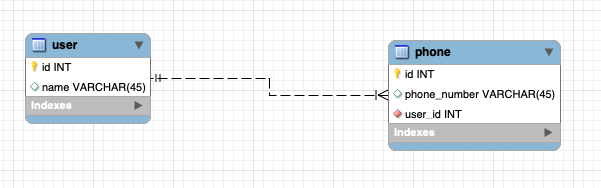
위 그림과 같이 하나의 유저가 여러 핸드폰 번호를 가질 수 있는 구조이다. 이는 관계형 데이터베이스에서 가장 많이 사용하는 구조이다.
N:N 관계
여러 레코드가 다른 테이블의 여러 레코드와 관계가 있는 경우로,

위 그림과 같이 고객 한 명은 여러 개의 여행 상품이 구매 가능하고, 여행 상품 하나는 여러 명의 고객이 구매할 수 있기 때문에 N:N관계를 1:N 관계로 분리하여 customer_has_package테이블로 묶어준다.
자기참조 관계
자기참조 관계는 1:N관계와 유사하지만, 참조되어야 하는 속성이 자신의 테이블에 있을 때를 말한다.

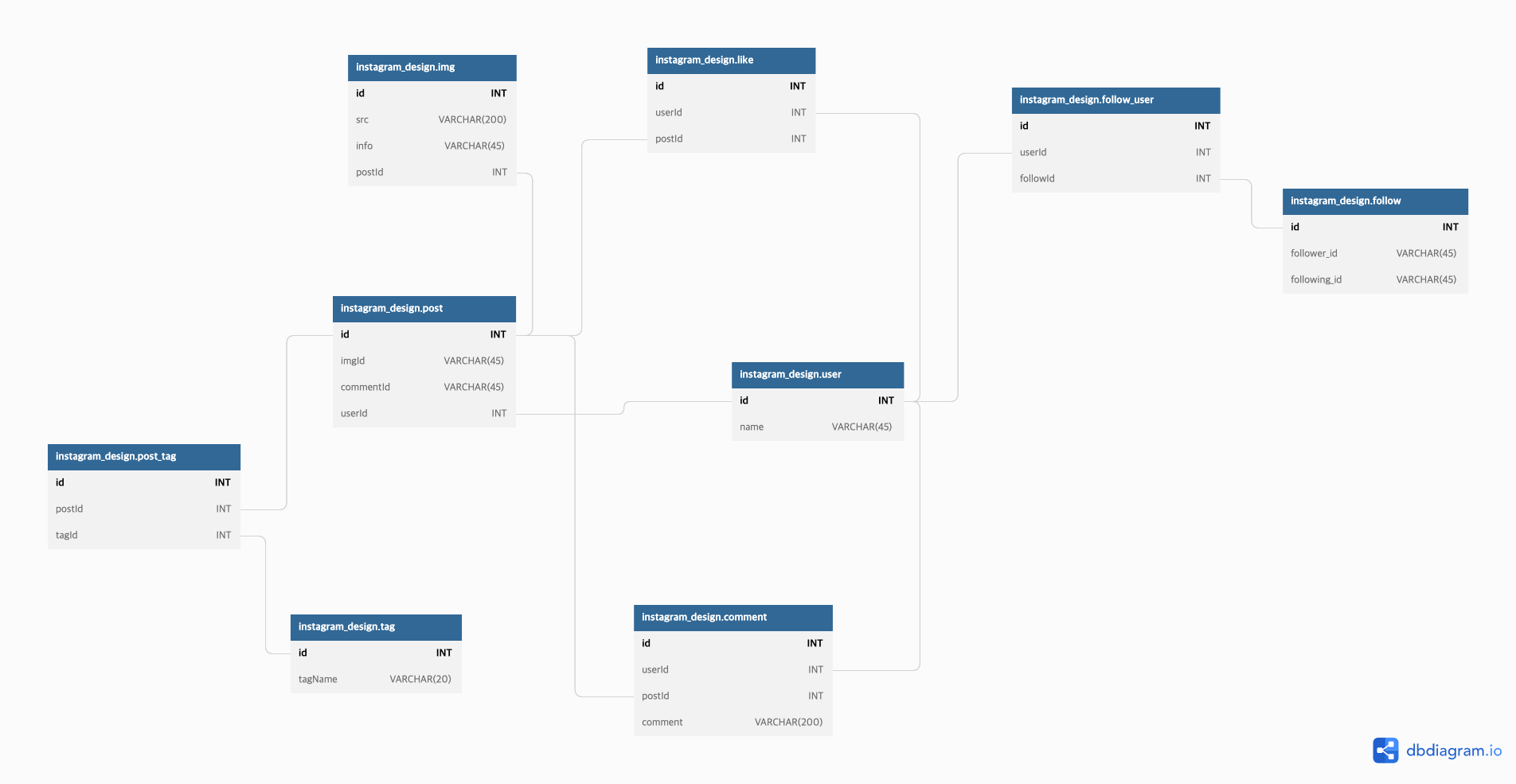
Ex. 간단한 인스타그램 스키마 설계
- 게시물
- 여러 개의 사진 : 1:N 관계
- 게시물 댓글
- 여러 사용자가 - 여러 댓글 : N:N 관계
- 해시태그
- 여러 태그가 여러 게시물 : N:N 관계
- follow
- 여러 사용자가 여러 팔로워, 팔로잉 : N:N 관계
- 좋아요
- 여러 사용자가 여러 게시물에 대해 좋아요 : N:N 관계
+ 데이터베이스 정규화(Database Normalization)
데이터베이스 정규화는 데이터베이스 설계시 데이터를 효율적으로 관리하기 위해 고려해야할 요소이다.
이는
- Data redundancy
- Data integrity
- Anomaly
로 구성되어 있다.
데이터 중복(Data Redundancy)
데이터 중복은 실제 데이터의 복사본이나 부분적인 복사본을 뜻하는데, 이러한 중복은 데이터를 복구할 때는 유용하게 사용될 수 있지만,
- 일관된 자료 처리의 어려움
- 저장 공간 낭비
- 데이터 효율성 감소
등의 문제를 가진다.
데이터 정규화(Data Integrity)
데이터 정규화는 데이터의 수명 주기 동안 정확성과 일관성을 유지하는 것을 뜻하는데, 이는 데이터의 무결성을 강화하는 목적도 가진다.
데이터 이상 현상(Anomaly)
데이터 이상현상은
- 갱신 이상(Update Anomaly)
- 삽입 이상(Insertion Anomaly)
- 삭제 이상(Deletion Anomaly)
으로 나뉘며 기대한 데이터와 다른 이상 현상을 나타낸다.
갱신 이상(Update Anomaly)
갱신 이상은 여러 행에 동일한 데이터가 있을 때, 어떤 행을 갱신해야 할 지 명확히 정의가 안되어 있는 경우이다.
삽입 이상(Insertion Anomaly)
삽입 이상은 삽입할 데이터가 명확하게 정해지지 않아 삽입하지 못하는 경우이다.
삭제 이상(Deletion Anomaly)
삭제 이상은 데이터의 특정 부분을 지울 때 의도치 않게 다른 부분도 지우는 경우이다.
+ SQL 종류
SQL에서 역할에 따라 문법을 분류한다.
- Data Definition Language
- Data Manipulation Language
- Data Control Language
- Data Query Language
- Data Transaction Control Language
Data Definition Language
DDL은 데이터를 정의할 때 사용되는 언어로, 테이블과 같은 오브젝트를 만들거나 삭제할 때 등이 해당된다.
Ex. CREATE, DROP
Data Manipulation Language
DML은 데이터베이스에 데이터를 저장할 때 사용하는 언어이다.
Ex. DELETE, INSERT, UPDATE
Data Control Language
DCL은 데이터베이스에 대한 접근 권한과 관련한 언어로, 유저에 대한 권한을 정한다.
Ex. GRANT, REVOKE
Data Query Language
DQL은 정해진 스키마 내에서 쿼리할 수 있는 언어로, DQL을 DML을 일부분으로 취급하기도 한다.
Ex. SELECT
Data Transaction Control Language
TCL은 DML을 거친 데이터의 변경사항을 수정할 수 있는 언어이다.
Ex. COMMIT, ROLLBACK
본 포스팅은 코드스테이츠 BEB 과정을 수강하며 작성한 글입니다.